在上一篇文章中,我们已经搭建好了三台可以互相ping通的centos7的环境了,现在接着上一篇来继续搭建hadoop的环境。
创建hadoop用户
1.创建hadoop用户
以后都会使用hadoop这个用户来操作,不再使用root用户!!!
useradd hadoop
passwd hadoop

三台虚拟机都添加相应的账户:hadoop。
2.给hadoop添加权限:(当前是root用户)
vim /etc/sudoers
在root的下面添加:
hadoop ALL=(ALL) ALL

3.在/opt目录下,创建:sofes目录和modules目录。
sofes:用来存储一些软件的压缩包
modules:用来存储软件的解压缩后文件。
cd /opt
mkdir sofes modules

3.将/opt文件夹的所有者指定为hadoop用户
sudo chown -R hadoop:hadoop /opt

下载java8和hadoop
切换到:hadoop用户
su hadoop
1)Java8 和 hadoop 到相应的官网去下载即可。
2)将java8和hadoop的压缩包上传到:/opt/sofes目录下:
使用:rz命令即可
版本:java是8,hadoop是3.x.x

3) 解压缩包
tar -zxvf jdk-8u221-linux-x64.tar.gz -C /opt/modules
tar -zxvf hadoop-3.2.2.tar.gz -C /opt/modules

删除centos7自带的java环境
1)查看是否有java的环境
先测试是否有java的环境:
java -version
如果出现:java的版本信息,就需要删除掉。
因为:hadoop需要使用jdk的环境,自带不行,需要Oracle的java环境。
2)删除java的环境
1. 查找java的环境
rpm -qa | grep java
python-javapackages-3.4.1-11.el7.noarch
java-1.8.0-openjdk-headless-1.8.0.161-2.b14.el7.x86_64
javapackages-tools-3.4.1-11.el7.noarch
tzdata-java-2018c-1.el7.noarch
java-1.8.0-openjdk-1.8.0.161-2.b14.el7.x86_64
2. 删除java的环境
rpm -e --nodeps java-1.8.0-openjdk-headless-1.8.0.161-2.b14.el7.x86_64
rpm -e --nodeps java-1.8.0-openjdk-1.8.0.161-2.b14.el7.x86_64

查找后:应该只剩下三行。
PS:如果上述权限不够,请先切换到root用户下
配置环境变量
vim /etc/profile
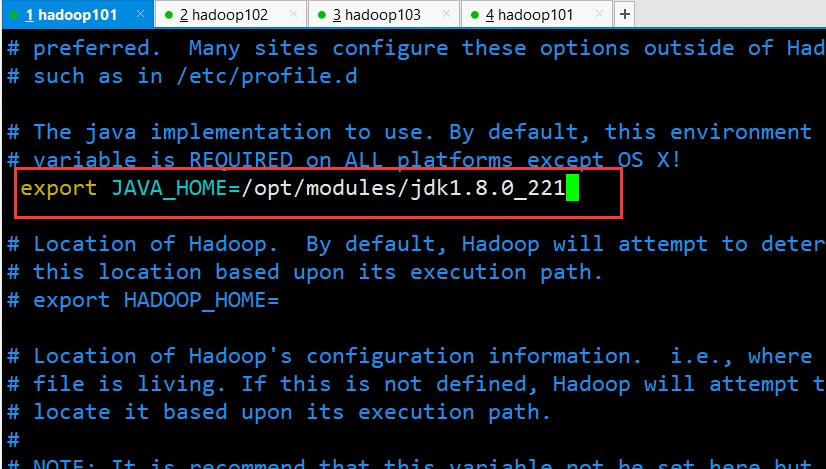
#JAVA_HOME
export JAVA_HOME=/opt/modules/jdk1.8.0_221
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
#HADOOP_HOME
export HADOOP_HOME=/opt/modules/hadoop-3.2.2
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin

刷新配置文件:
source /etc/profile

hadoop运行模式
本地运行模式
运行官方的Gerp例子
注意:切换到hadoop用户
$ mkdir input
$ cp conf/*.xml input
$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.2.jar grep input output 'dfs[a-z.]+'
$ cat output/*

查看:output目录

我们,可以看到:有两个文件:1)part-r-0000;2)_SUCCESS
part-r-0000就是运行mr的结果:



运行官方的wc案例
word-count的案例:就相当于编程语言中的”hello world”例子。
在hadoop的根目录下:
mkdir wcinput
cd wcinput
touch wc.input
vim wc.input
hadoop java
hadoop yarn
mapreduce spark
保存退出,回到hadoop的根目录下:
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.2.jar wordcount wcinput wcoutput


运行结果:

能看到结果是,将wcinput文件夹下面的所有文件按行处理,每行按照空格切割,将切割后的单词进行数量统计。
本地单机运行模式,默认采用的是本地的文件系统,所以我们创建的文件夹、文件,最后输出的文件夹都是采用的是Linux的文件系统,保存在本地。
伪分布运行模型
伪分布模型就是在一台机器上面,运行hadoop的各个组件,包括namenode和datanode,启动环境运行。
配置 hadoop-env.sh
添加java的环境变量
vim /etc/hadoop/hadoop-env.sh
export JAVA_HOME=/opt/modules/jdk1.8.0_211
修改 core-site.xml:
vim /etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop101:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/modules/hadoop-3.2.2/data/tmp</value>
</property>
</configuration>
1)设置:hadoop的文件系统为:hdfs,指定namenode的运行节点
可以查看默认的配置:
http://www.hadoop.org/hadoop-project-dist/hadoop-common/core-default.xml
2)设置:hadoop运行时产生文件时所使用的目录


修改 hdfs-site.xml:
vim /etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
设置:hdfs的副本数为1,默认为3。伪分布模式,一台机器,设置成3没有意义,因此修改默认的配置为:1

启动集群
1)格式化:NameNode(第一次启动的时候才格式化,以后就不要总格式化)
bin/hdfs namenode -format
如果严格按照上述配置执行,那格式化namenode是不会失败的,如果失败,请到各个节点的tmp路径进行删除操作,然后重新格式化namenode。

namenode格式化成功: 在我们配置的namenode生成文件目录下,可以看到信息:

2)启动:NameNode
sbin/hadoop-daemon.sh start namenode
3)启动:DataNode
sbin/hadoop-daemon.sh start datanode

以后请使用:hdfs --daemon start
查看集群
1)查看是否成功
jps
6674 Jps
6518 DataNode
6426 NameNode

2)打开浏览器:hadoop101:9870
注意:hadoop2的端口号是:50070

3)使用hdfs的命令来简单使用
bin/hdfs dfs -ls /
显示为空,啥也没有查询到,因为目前就是为空!
然后,可以通过浏览器来验证:

创建目录:
bin/hdfs dfs -mkdir -p /usr/gakki/wcinput



上传文件:
bin/hdfs dfs -put wcinput/wc.input /usr/gakki/wcinput/
bin/hdfs dfs -ls /usr/gakki/wcinput/


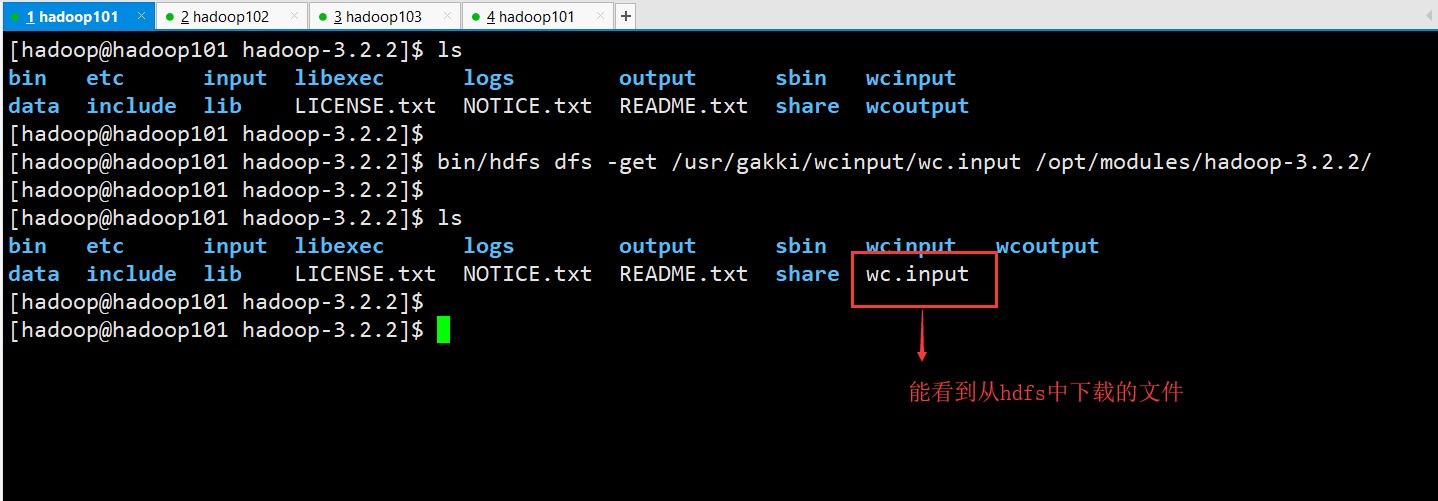
可以看到:wc.input上传成功!
注意:我们的wc.input的文件只有50B,但是hdfs帮我们分配了一个块的大小是:128MB可以下载我们上传的文件:


命令来下载hdfs上面的文件
bin/hdfs dfs -get /usr/gakki/wcinput/wc.input /opt/modules/hadoop-3.2.2/
查看namenode和datanode的运行日志:
运行的日志目录是在:$HADOOP_HOME/logs目录下

大家如果运行错误,可以查看这个两个日志运行目录,进行排查问题。
在HDFS上运行WC案例
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.2.jar wordcount /usr/gakki/wcinput/wc.input /usr/gakki/wcoutput
bin/hdfs dfs -cat /usr/gakki/wcoutput/p*


使用YARN启动MR
1)配置:yarn-env.sh
增加JAVA_HOME的环境:
export JAVA_HOME=/opt/modules/jdk1.8.0_211
请注意:hadoop3不需要配置了。

可以看到:hadoop-env.sh已经修改java的环境变量,就不需要修改 yarn-env.sh了;yarn-env.sh的配置会覆盖hadoop-env.sh的配置。
2)配置:yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop101</value>
</property>
</configuration>
3)配置:mapred-env.sh
增加JAVA_HOME的环境变量
export JAVA_HOME=/opt/modules/jdk1.8.0_211
和yarn-env.sh一样。
4)配置:mapred-site.xml
hadoop2的没有mapred-site.xml,有一个mapred-site.xml.template,然后修改它的名字为:mapred-site.xml
mv mapred-site.xml.template mapred-site.xml
hadoop3本身就有。
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
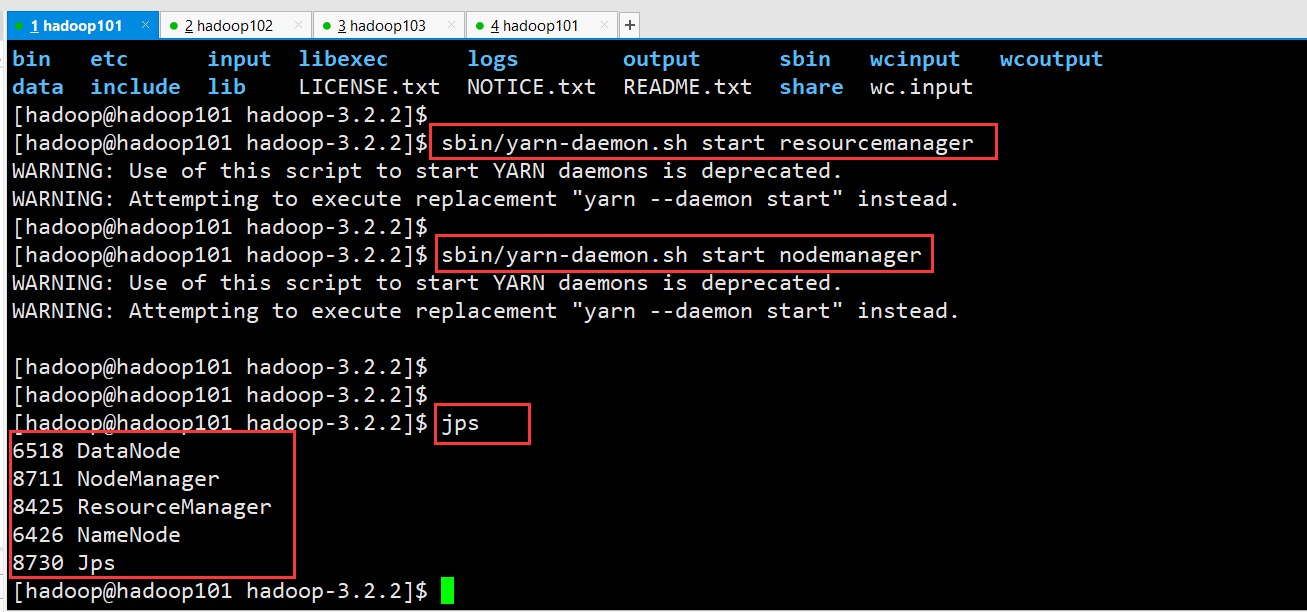
5)启动:resourcemanager
sbin/yarn-daemon.sh start resourcemanager
该命令已经过期:请使用 yarn –daemon start resourcemanager
6)启动:nodemanager
sbin/yarn-daemon.sh start nodemanager
该命令已经过期:请使用 yarn –daemon start nodemanager
7)查看状态
jps
打开浏览器:hadoop101:8088

8)运行wc案例
首先删除:/usr/gakki/wcoutput
bin/hdfs dfs -rm -r /usr/gakki/wcoutput


启动wc的mr任务:
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.2.jar wordcount /usr/gakki/wcinput/wc.input /usr/gakki/wcoutput
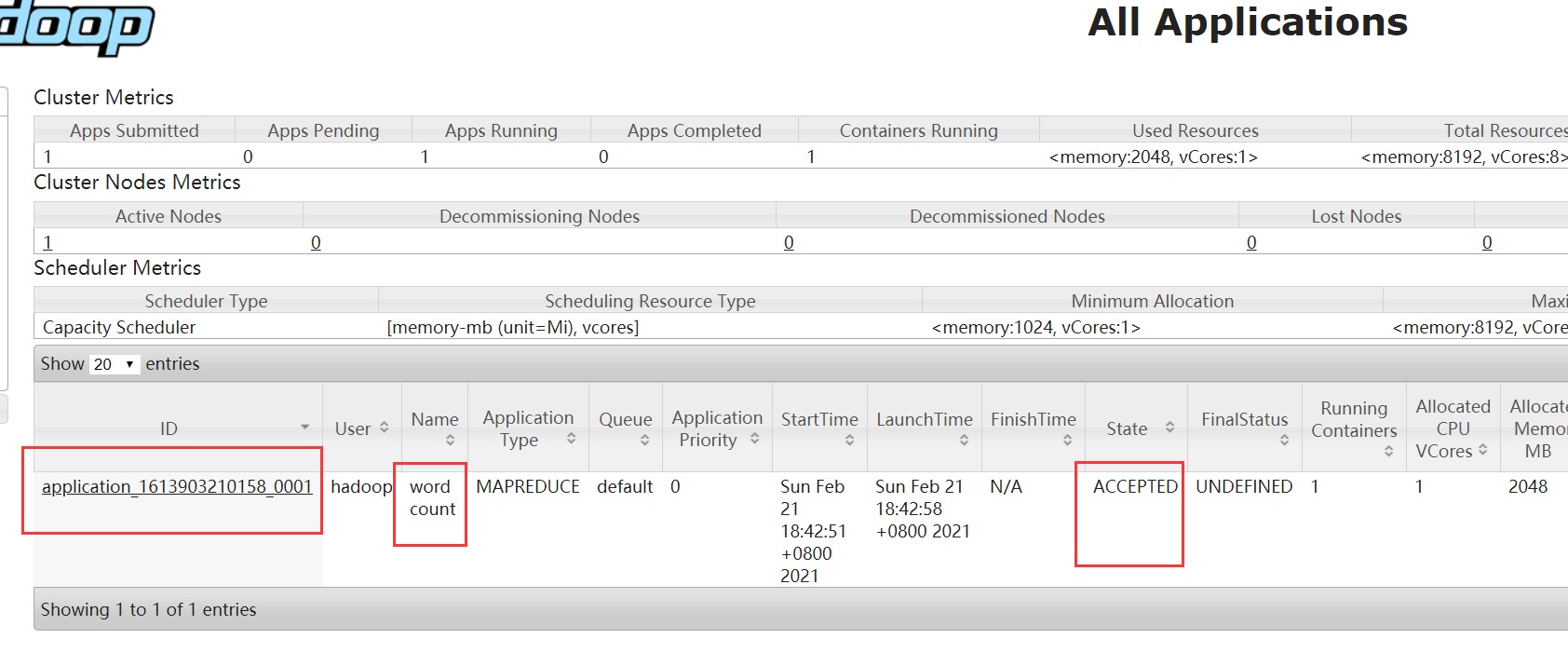
能看到我们任务在yarn上面准备开始运行。
然后看,控制台出现错误:

解决问题:
1) hadoop classpath
出现很多classpath的路径,将这些路径添加到yarn的配置文件中。
2) 修改 yarn.site.xml
<property>
<name>yarn.application.classpath</name>
<value>xxxxx</value>
</property>


停止:resourcemanager、nodemanager
开启:resourcemanager、nodemanager
yarn --daemon stop resourcemanager
yarn --daemon stop nodemanager
yarn --daemon start resourcemanager
yarn --daemon start nodemanager


重新运行wc的mr任务:




配置历史服务器
vim mapred-site.xml
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop101:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.https.address</name>
<value>hadoop101:19888</value>
</property>
启动:历史日志服务器
sbin/mr-jobhistory-daemon.sh start historyserver
命令过期:
mapred --daemon start historyserver
查看:jps

打开浏览器:hadoop101:19888


配置日志的聚集
默认的yarn的日志聚集是关闭:
yarn.log-aggregation-enable = false

vim yarn-site.xml
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
开启日志聚集,并且保存7天
重启:resourcemanager、nodemanager、historyserver
yarn --daemon stop resourcemanager
yarn --daemon stop nodemanager
mapred --daemon stop historyserver
yarn --daemon start resourcemanager
yarn --daemon start nodemanager
mapred --daemon start historyserver

删除wc的hdfs上面的路径,再次运行wc任务:


端口号总结
hdfs的端口号:9870
yarn的端口号:8088
历史服务端口:19888



